Act 2: Make it fast
Act 1 ended with a working inference engine and a deliberate disappointment: model-generate produces coherent text from a real Qwen3 checkpoint, and it takes about a second per token to do it, slower with every step. That is the baseline. Act 2 is the work of making one request fast: not a server, not many users, just a single prompt turned into a single response as quickly as a laptop can manage.
The temptation is to start guessing. Maybe the matmul is slow; maybe it's the attention; maybe Rust needs a --release flag somewhere. Guessing is how you spend a week speeding up code that was never the bottleneck. So Act 2 has one rule, and the first chapter exists only to enforce it: you cannot optimize what you have not measured. Every chapter after the first earns its place by moving a number that the first chapter taught us to print.
The two workloads hiding inside one request
Before the ladder, one idea you need in your head, because every optimization in Act 2 leans on it.
Generating a response is not one kind of work. It is two, stapled together:
- Prefill is the part where the model reads your prompt. All
Pprompt tokens go through the network at once, in one pass. Internally this is a sequence of big matrix-by-matrix multiplications. It is compute-bound: the chip is busy doing arithmetic, and the way to make it faster is to do that arithmetic faster: more lanes, more cores, a GPU. - Decode is the part where the model writes the response. It produces tokens one at a time: run the network, get one token, feed it back in, run again. Each of those passes processes a single token, so the big matrix-by-matrix multiplications shrink into matrix-by-vector multiplications. A matrix-vector product barely uses the chip's arithmetic units; almost all the time goes to reading the model's weights out of memory. Decode is memory-bandwidth-bound. Faster arithmetic helps only until the reads become the bottleneck: one round of it (SIMD, in II.3) buys a real speedup, and after that decode is up against the bandwidth wall. From there, only reading fewer bytes helps.

Figure: the same weights, two shapes of work. Prefill amortizes each weight read across the whole prompt; decode cannot.
Hold onto that split. When the KV cache delivers a huge speedup in II.2, it's because it fixes decode. When threads and the GPU speed up prefill but leave decode flat, it's because they attack compute, and by then decode's problem isn't compute. When Q8_0 quantization speeds decode up 2.3× in II.6, it's because it cuts the bytes each token reads roughly in half overall (the weights shrink ~4×; everything else stays FP32). Bytes are decode's whole story.
The ladder

Figure: the ladder, with the numbers each rung actually measured.
Six chapters, each a rung. Each one is benchmarked in the harness built in the first.
Figure: Act II at a glance. Each chapter moves a measured number; each builds on the one above.
- II.1: Benchmark harness. A
Metricstype wired into the generation loop: time-to-first-token, decode throughput in tokens/second, and the duration of every individual forward pass. No optimization yet. This is the instrument the rest of the act answers to, and the baseline number we measure everything against. - II.2: KV cache. The single biggest win in the act. Without it, generating token N re-runs the whole network over all N prior tokens. With it, each new token costs one forward step. We split
forwardinto a prefill path and a decode path, add aBasicKvCachethat stores per-layer keys and values, and turn it on with--kv. - II.3: SIMD CPU backend. A second
Backendimplementation that uses the CPU's NEON vector instructions to do matmul 4 lanes (and with unrolling, 16) at a time. It delegates everything that isn't matmul to the scalar backend from Act 1. Selected with--backend simd. - II.4: Multithreaded CPU backend. A
Backendthat wraps the SIMD one and spreads matmul across every core withrayon, Rust's data-parallelism library. Prefill, which is compute-bound, speeds up 5.1× across ten cores.--backend parallel. - II.5: Metal GPU backend. A
Backendthat runs matmul on the GPU. We write the kernel in Metal Shading Language, drive it through command buffers (the batches of work you queue up for a GPU), and exploit Apple Silicon's unified memory so the CPU and GPU share the same bytes with no copy.--backend metal. - II.6: Q8_0 quantization. So far we've been running the FP32 export of the checkpoint: four bytes per weight, on disk and in memory. Qwen3 also ships as a Q8_0 export, an 8-bit quantized format at roughly a quarter the bytes. This chapter switches to that file, keeps the weights quantized in memory, and multiplies against them directly. Fewer bytes read means decode, which is bandwidth-bound, gets 2.3× faster.
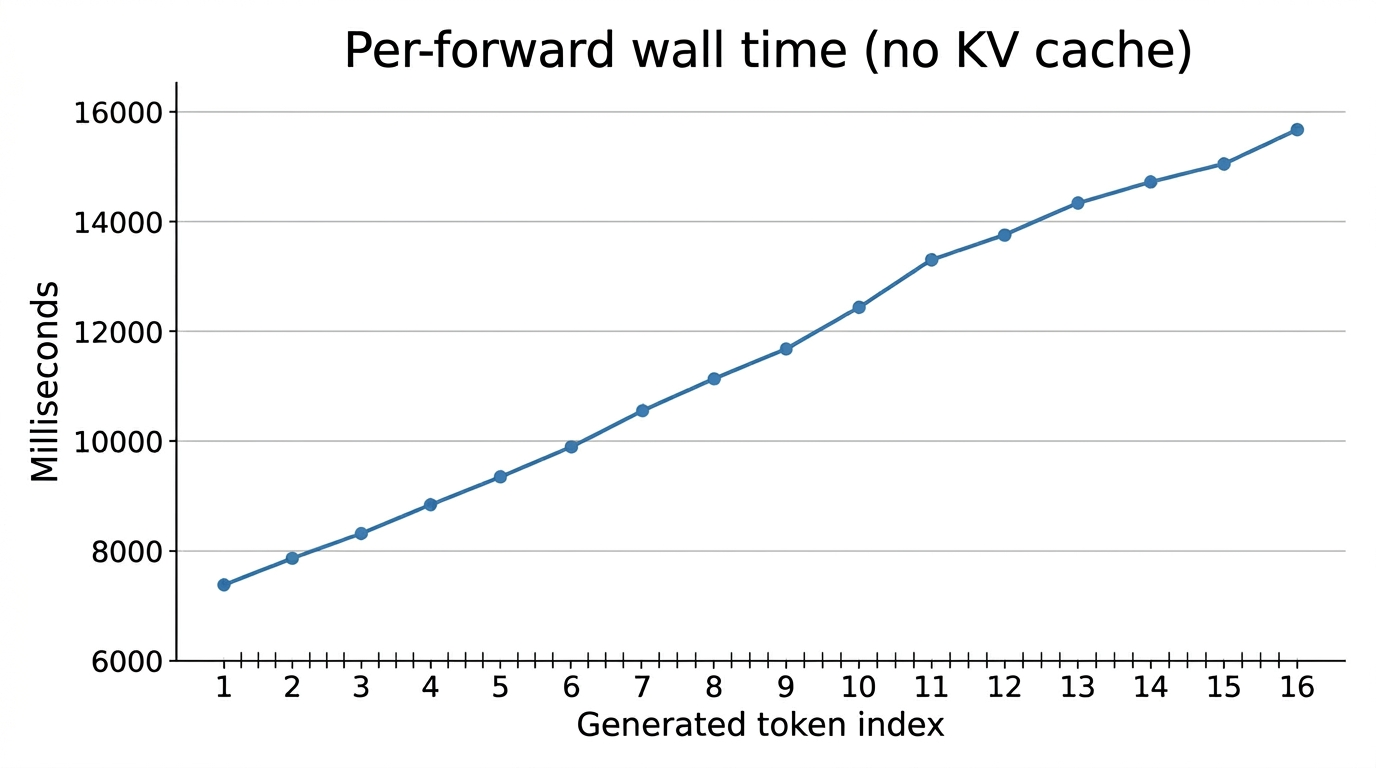
Figure: per-token forward duration across Act II. The KV cache is the biggest single jump; SIMD, threading, and Metal compound from there.
What "done" looks like
At the end of Act 2, model-generate --kv --backend metal "Once upon a time, in a small village by the sea, there lived a baker" runs the same Qwen3 0.6B checkpoint from Act 1, end-to-end, fast. Every speedup between the Act 1 baseline and here is attributable to one specific chapter, and provable in the harness from chapter one. You will know which rung moved the number and why: prefill versus decode, compute versus bandwidth.
What we have not done by the end of Act 2: served the engine to anyone. There is still just a CLI binary. No HTTP, no streaming, no chat formatting, no second concurrent request. That is a different problem, and it is all of Act 3.
Start with II.1: Benchmark harness.